

TL;DR: The tech and skills required for AI solution delivery sit at the intersection of software and data engineering. To ensure the successful delivery of AI initiatives, organisations must bring these key capabilities together into value-aligned delivery teams.
I recently worked on developing a digital banking platform that we could take from idea to user hands and pass a full Australian Prudential Regulation Authority (APRA) audit within 9 months. This accelerated project delivery was possible only due to early alignment between the data and software engineering teams.
As our client stated,
We implemented your suggestions and got huge gains in all the places we cared about - shorter development time, much easier for teams to adopt, getting data users up to date in minutes or hours, instead of weeks or months as it had been previously.
Integrating data and software engineering earlier in the product life cycle is especially crucial to the successful delivery of AI projects. Business outcomes include:
Reduced delivery costs, with AI projects running in production on budget and on time.
Increased user adoption and trust due to high-quality AI responses, as AI systems always have access to the latest data.
Reduced operational costs due to fewer incidents in AI training pipelines.
This blog discusses data requirements of AI features and three key steps to achieving early data alignment.
Requirements of AI-Integrated Software Products
AI is quickly becoming the engine of product differentiation, operational efficiency, and customer delight. AI-integrated software products offer an immersive and highly interactive experience and can respond dynamically to natural language conversations, user behaviours, and social and global trends.
However, AI features like recommendations, personalisation, and chat-based assistance depend on the software product’s ability to ingest current user interaction data and enrich it with context and external knowledge. Every interaction a user has with the product immediately generates data that can shape the user’s next experience.
For example, in a retail software product, users' likes and purchases provide data for future recommendations. If a user asks detailed questions about item specifications through chat, the product can use that information to suggest similar items at different price ranges.
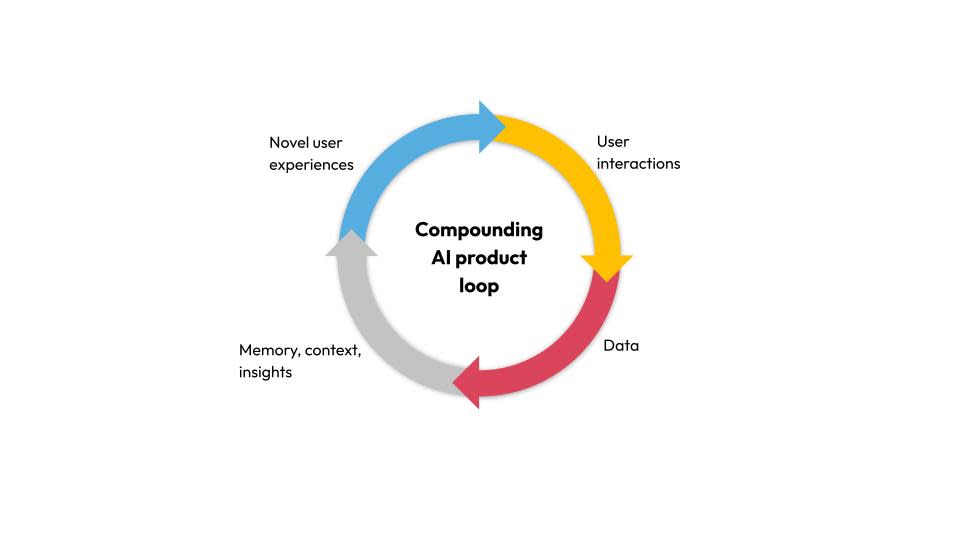
The sooner user data is available for AI training and context enrichment, the better the product meets user expectations. Data has a domino effect: high-quality data supports the development of more advanced features, which in turn raise user engagement and yield even more data.
By using their data effectively, organisations can develop products that meet market requirements more quickly than companies relying on traditional data analytics.
Challenges with Traditional Approaches
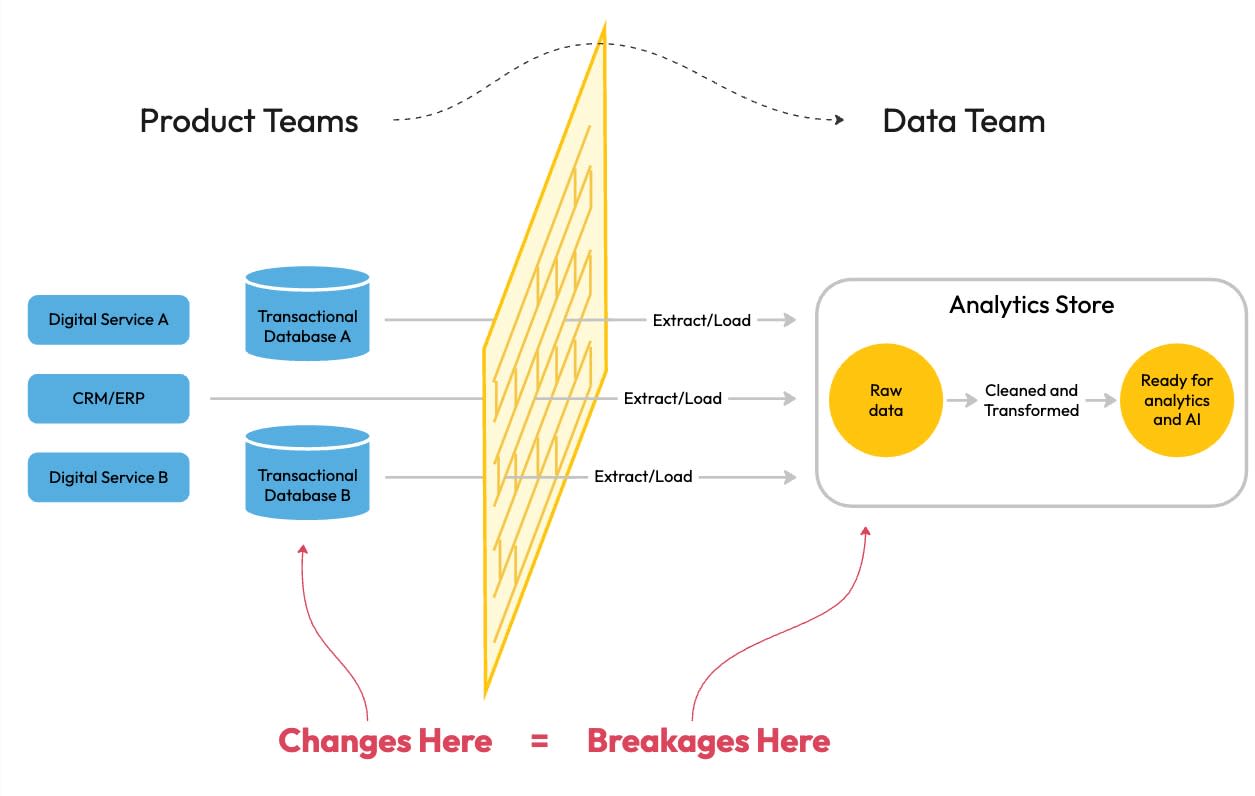
Traditionally, the product team designs and builds the product features. Any data generated by software products is moved for further analytics in an Extract, Load, Transform (ELT) pattern. Application data from operational systems is moved into a centralised data store (like a data lake or a data lakehouse) in periodic updates. The data team prepares the data for analytics and feeds it back to any AI models for retraining and improving AI feature behaviour in the product.
Decoupling data and product teams in this way results in the following negative outcomes.
Applications lack access to immediate user intent and implicit temporal context because data is extracted from operational systems at a later stage.
Data teams are forced to rediscover and reimplement business rules already implemented upstream in software.
Product teams are pulled into expensive change management cycles, coordinating every schema update with downstream data consumers.
Data pipelines break unexpectedly when changes go unmanaged, eroding trust in data and increasing operational risk.
With AI, the boundary between transactional, operational, and analytical data collapses. Teams that cannot execute in lockstep on both the software and data capabilities of the product are forced into handoff flows, rework, low-quality data, and a poorer customer experience.
Extract, Load, Transform
The Fix - Product and Data Alignment
Organisations can improve both AI product outcomes and data quality for other analytics by moving data ownership earlier in the lifecycle. This approach positions data assets as first-class deliverables of the product development lifecycle and mandates data asset ownership on the product development team.
This pivot rests on three pillars:
Cross-functional teams that own code and data together
An event-driven, real-time data ecosystem
Intelligent platforms that enable rapid and safe delivery by both humans and agents.
Cross-Functional Data + Product Teams
Product engineers have traditionally been experts in software engineering. Their skill sets include business process and business domain modelling, low-latency transaction processing, OLTP database management, frontend development, and REST APIs.
These skills are no longer sufficient for successful modern AI product development. Various tools and technologies are required for delivering anything beyond simple AI proofs-of-concept. Many software engineering teams may lack the skills and experience necessary for developing, running, and operating RAG pipelines, vector data stores, prompt safety frameworks, and agentic architectures.
In our work with clients, we frequently encounter a lack of embedded capabilities, leading to duplicated prototypes that never reach production, stalled rollouts, security red flags, and negative organisational attitudes towards AI-centric initiatives. We recommend organisations integrate data expertise and ownership directly into customer-facing product teams to bridge the engineering skillset gap and unlock the data and AI innovation capabilities necessary for successful AI product development.
Event-Driven Data Ecosystem
To move beyond the handoff-centric data operating model, product teams must shift from retrospective data extraction to real-time business event capture. This requires two paradigm shifts in data management technologies.
Treat Data as a Product
Data as a product (DaaP) treats data sets as standalone products, designed, built, and maintained for data product “customers” such as engineers, analysts, and AI agents. The data product contains data values along with standard metadata, approved storage formats, consistent classification tiers, and uniform access protocols. It is discoverable, addressable, and dependable.
Organisations should manage data products with the same rigour as software APIs, with versioning, documentation, and publication in an internal catalogue to track lineage and real-time usage.
Event-Driven Architecture (EDA)
Event-driven architecture (EDA) is a design approach where systems communicate with each other through events—messages that signal something has happened (e.g., “OrderPlaced” or “CustomerSignedUp”). It offers a powerful foundation for capturing business-critical changes as they happen, directly from the source of truth.
Organisations should utilise EDA for building streaming data products. These data products are real-time, reusable outputs built on continuously flowing data, such as click events, transactions, sensor readings, or user interactions. A streaming data product might be:
A real-time dashboard of customer activity
A live fraud detection service
An up-to-date inventory view
A continuously updating user behaviour model
They capture the core business state at the time of occurrence, carrying context and intention, which eliminates downstream guesswork.
Streaming data products unlock fresh, contextual inputs for AI use cases. They also align with advanced, agentic AI architectures, where autonomous software AI agents can subscribe to and act upon live business events in real-time.
EDA closes the loop between digital execution and data insight, enabling cross-functional teams to move faster, with trust and intelligence built in from the start.
Intelligent Platforms
Intelligent platforms extend traditional platform engineering to support the full lifecycle of data products and AI-enabled capabilities. While conventional platforms focus on accelerating software delivery through abstractions like CI/CD, infrastructure as code, and observability, intelligent platforms treat data and AI as first-class citizens: integrated, governed, and accessible by design.
They act as enablers of AI-accelerated development. For example, they support:
Data discovery and governance
Model development and deployment
Compliance and risk controls
AI agent interactions with the platform
They can also integrate deeply with enterprise data and context, exposing business logic, domain models, policies, and standards in a way that AI features and tooling can use this information to meet end-user needs better.
Getting Started with Aligning Product-Data Delivery
Most organisations start at a foundational maturity level where data and product are siloed. Infrastructure is manually managed, and data work is mostly reactive and report-driven. AI efforts are experimental, with informal governance and limited traceability. Organisations at this stage struggle with scalability and repeatability.
The target state is full integration of data and product teams. The platform is agent-ready, meaning AI agents can interact with it intelligently and safely. Code and data pipelines share unified continuous integration flows, while AI agents scaffold and evolve systems using governed access to enterprise context. Governance is fully automated, with real-time policy enforcement, auditability, and trust built into every layer.
To move from the current to the target maturity level, organisations should:
Adopt product thinking in both data and platform teams
Automate infrastructure and governance to reduce risk and manual effort
Build AI enablement into the platform itself, not as a bolt-on.
Federate ownership and policy enforcement, ensuring teams have autonomy within guardrails.
Invest in metadata, lineage, and quality tooling to support trustworthy AI and analytics.
Contact V2 to discover how our consultants can support you in your data-product integration, analyse where you are at, and work with your team to fill the gaps.




