

TL;DR As an organisation’s machine learning and artificial intelligence (ML/AI) systems evolve, it becomes increasingly important to manage artefacts, code, and environments in a systematic manner akin to software engineering. Without that, creating and updating production-ready models becomes time-consuming and error-prone. This blog explores how education sector organisations can use the Databricks analytics platform to streamline machine learning and artificial intelligence (ML/AI) projects at scale.
New ML and AI model development typically begins in the data scientist’s local environment. Models are run on request, training data is manually extracted, and model versioning is performed ad hoc by the data scientist via file and folder naming schemes. While this approach works initially, an inflection point occurs when model management tasks begin to divert time away from innovation.
For example, at a recent client engagement at a leading Australian university, their data scientists had developed eight early-stage predictive models to identify students at risk of disengagement. However, their manual approach to model management was resource-intensive and dependent on a few key individuals. Updating models with the latest student information was time-consuming and tedious. Report generation was only possible a few times a year, limiting the university’s ability to use and act upon the insights generated.
Our V2 AI team utilised the Databricks platform to help our client modernise and optimise their models and environment, and move to production in a matter of weeks. Databricks-native capabilities enabled enhancements in performance, scalability, and maintainability across the board.
Measurable business outcomes included:
Faster time to predictions by accelerating the development and deployment of models.
Engineering and team uplift by instilling best practices for managing multiple productionised models on a modern data platform.
Innovation at scale, as data teams can focus their efforts on deriving new value through other initiatives rather than model maintenance.
Models can now be updated with the latest student data on demand, allowing the university to identify and support disengaging students in time, directly impacting academic success and student well-being.
The Role of MLOps in Taking ML/AI to Production
Per the Databricks documentation, “MLOps (Machine Learning Operations) is a set of processes and automated steps for managing code, data, and models to improve performance, stability, and long-term efficiency of ML systems.“
These processes and practices include:
Code management processes, such as branching policies and continuous integration workflows for testing
Data asset governance policies, like access controls
Continuous deployment workflows to reduce the effort in promoting models to production
Automated training and inference pipelines
Automated monitoring to catch model drift, and automated retraining of models should drift occur
Documented ways of working
In practice, MLOps separates the concerns of creating and managing models, while providing a robust development workflow for moving from model inception to running in production for the long term.
Databricks Features for MLOps
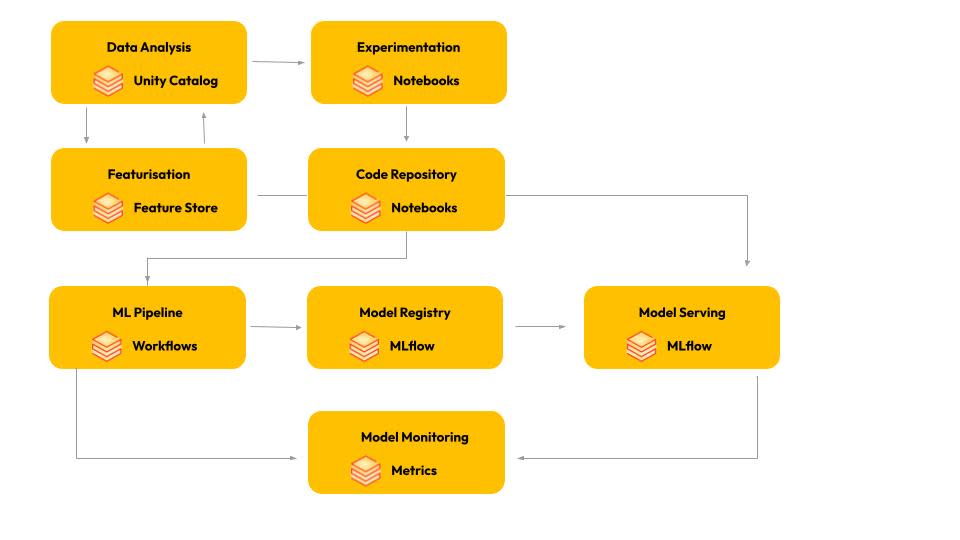
Databricks features for different aspects of the machine learning workflow
Databricks, as a platform, has many built-in features to support a production-ready MLOps implementation. For example, it provides:
Built-in access to MLflow, the popular open-source developer platform for tracking experiments, model versioning, model registry, and collaborating on projects.
Unity Catalog, a centralised data catalog that provides flexible and powerful governance for all models and data on Databricks.
Feature Store, a centralised repository to manage the lifecycle of ML features, enhances discoverability for common features and ensures consistency in feature derivations across models.
You also get automated data lineage for data discoverability and traceability.
With Databricks Workflows as a means of orchestration, you can schedule and chain your ML processes like feature engineering, training, and inference. You can also monitor and observe the status, logs, and results of each step directly from the Databricks interface.
Lastly, as Databricks is an Apache Spark™ based platform, you get the benefit of large-scale parallel computing and can run efficient feature engineering transformations on continuously growing datasets. It also provides a mature data streaming toolset for real-time analytics.
MLOps Stacks
A key benefit of utilising Databricks for MLOps is the built-in support for generating templated projects with MLOps Stacks. MLOps Stacks is a templated Databricks Asset Bundle repo, used to provide a complete configuration for the model development process with industry-standard MLOps practices.
It consists of a default configuration for repo structure, workflow orchestration, and CI/CD pipelines, allowing you to fast-track the creation of a production-ready ML project on Databricks.
Customising the Databricks Environment for our Client in the Education Sector
Initially, you can use MLOps Stacks to quickly set up a shell of a project, complete with example logic. (See additional resources at the end of the blog for details)
But to make this project yours, the specific logic for the model you want to implement will need to be incorporated.
Complexity arises when customising the stack to suit the team’s needs and maturity, relocating existing ML code into the new repo, and implementing any changes needed as a result of migrating from local runs to hosted runs on Databricks.
As a starting point, the MLOps Stack includes instructions on how to complete the rest of your setup. They are provided in the form of README.md files that cover all bases, including CI/CD, model training, and testing.
Some of the things we did for our client include:
Set up CI/CD for Git Provider
While the pipelines for your specific git provider have already been created as a part of the stack, you need to set up the triggers and permissions for those pipelines.
We further opted to simplify the path to production by treating the main branch as the production branch. Any merged pull requests trigger a production deployment against main. This reduced complexity allowed our client’s small team to minimise governance steps and encourage self-reliance throughout the development-to-production lifecycle.
Migrate Existing Logic
We migrated existing feature engineering transformations, model training, and inference logic. Beyond lift and shift, we optimised the code to use Databricks' native functionality. For example:
Adding feature tables to the Feature Store
Updating so transformations can run against Unity Catalog tables
Convert pandas native code into pyspark-pandas and SQL to leverage the parallel computing performance uplift.
Reduced code complexity, like by removing custom logic to track model metadata and metrics, as this is built-in Databricks functionality
Set up Tests and Metrics
We facilitated testing and metrics within Databricks to improve model output quality. These metrics can also be used in monitoring the output of these models over time so that the client team can be alerted to drift or to trigger automated model retraining.
Outcomes and Impact of MLOps with Databricks for our Client
Introducing MLOps and Databricks to our client has helped introduce operational efficiencies and accelerate innovation. Uplifted data and AI capability have set the stage for future project expansion without compromising quality. Automation saves time, freeing the data team to generate more value for the business.
New Model Development Support
The client data team can now develop new models, test feature engineering code, and validate inferences all in the development environment against read-only production data. The models will all train and infer the same way, as the underlying dataset is the same across environments, ensuring consistency.
As new models are trained, they are logged in MLflow, where metrics and parameter history can be viewed later for further analysis. This is particularly useful for A/B testing previous and upcoming versions of the same model.
Automated Model Updates
Per the default behaviour of MLOps Stacks, the data team can raise pull requests against the main branch to automatically trigger build validations, unit tests, and integration testing. The code is temporarily promoted to the staging workspace, features are created, the model is trained on production data, and inference is performed against the target dataset. If successful, they can approve and merge the pull request, prompting a promotion to production.
The latest updated version of the model is flagged as the champion model and is used for automated batch scoring jobs in Databricks Workflows. The scoring jobs use MLflow’s model registry to identify the champion version of the model for prediction tasks. While we may have trained a new model in production, it must still pass all model validations before it is used to generate production predictions.
This ensures ongoing quality in the face of frequent data updates without manual intervention.
Automated Model Performance Tracking
As the production champion model is running on a schedule, built-in monitoring jobs allow the client’s data team to define thresholds for their existing metrics. If the model’s performance degrades to below-threshold standards, notifications are sent out, and if configured this way, the model is automatically retrained.
Key Takeaways
If you are just starting with Databricks, I suggest starting small and expanding from there. You don’t need to have every feature fully productionised from the get-go. Get your framework working for a small feature set and expand in scope as you solidify your processes.
Automate early. Basic CI/CD saves time, avoids errors, and codifies ways of working within the team. Implementing this early embeds best practices within the team.
Leverage native tools and features as much as possible. Unity Catalog, MLflow, and Feature Store simplify compliance and consistency. Orchestrate your train/validate/infer workflow using Databricks Jobs for observability.
As a Databricks partner, V2 AI enables organisations to implement Databricks at scale with full customisation and cost efficiency. Contact us to accelerate your Databricks adoption journey.
Additional Resources: Setting Up the Databricks MLOps Stack
The section below details how we used MLOps Stacks to get our client team started with ML on Databricks.
Step 1: Environment Preparation
Create at least three Databricks workspaces, one each for development, staging/testing, and production. You could separate staging and testing workspaces. Treat the testing environment as ephemeral integration testing, while staging can be used for longer-term pre-production testing.
Next, set up your Git hosting provider. Currently supported by MLOps Stacks are GitHub, Azure DevOps, and GitLab. You will need administrator permissions to create repos, change branching policies, and create Azure Pipelines.
Lastly, ensure your CI/CD pipelines have access to your Databricks workspaces. We opted to create Entra Service Principals for authentication and permissions management.
Step 2: Stack Instantiation
Install Databricks CLI and run databricks bundle init. It will provide you with an interactive session. Select `mlops-stacks` and answer the questions that follow. You will need to provide details like project name, branch names, user group name, etc. It will then set up a full repo that is almost ready to deploy straight to production.
Here’s a list of assets created for you.
Asset | Description |
Databricks Asset Bundle Definition | This allows you to promote this repo directly into your Databricks environment of choice. This can be done either locally or from your Git Provider in the form of a CI/CD pipeline. |
Databricks Resource Definitions | These are YAML files that define the creation of your Databricks Workflows for Feature Engineering, Model Training, Model Validation & Deployment, Batch Inference, and Ongoing Monitoring |
Feature Engineering | Notebook and example features to facilitate the creation of Feature Store registered features. |
Model Training | Notebook with example code on how to train the model and log the experiment in MLflow. |
Model Validation | Notebook and example definitions of validation logic you can use to define whether a model is of acceptable quality to be promoted to higher environments. |
Model Deployment | Code to manage models registered in the MLflow registry, and manage which of those models is deemed the ‘Champion’ version model that runs ongoing inferences. |
Tests | Code to facilitate running unit tests against the repo. Provided with pytest. |
Monitoring | Configuration to facilitate the tracking of metrics on an ongoing basis and trigger alerts or model retraining should metrics meet (or not meet) certain thresholds. |




